Using the Blast search:
To use the blast search for the transcriptomic database enter any of the following:
- Amino acid sequence in bare format (just amino acid 1-letter abreviations)
- Amino acid sequence in FASTA format with a heading starting with ">" (See explanation below)
- Accession Number starting with "NP_" or "XP_" (example: NP_037041)
- Swiss-Prot Number starting with a letter. (examples: P34080.1, Q5XIE3.1)
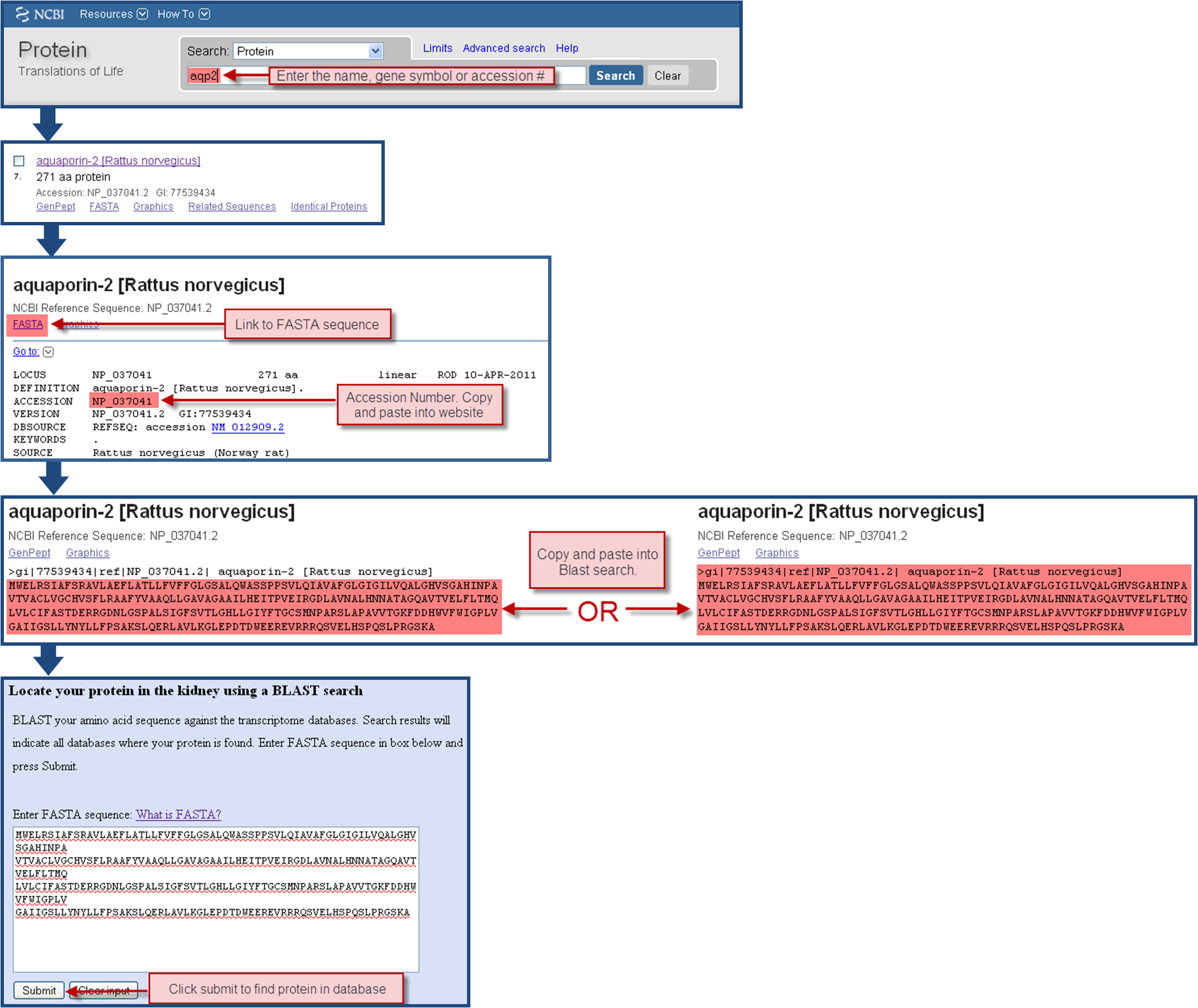
How to find an amino acid sequence for a specific protein:
A convenient method of finding an amino acid sequence or accession number of a protein is to use the Pubmed protein search and copy the FASTA amino acid sequence.
- First, go to the Pubmed protein search page (http://www.ncbi.nlm.nih.gov/protein).
- Enter the name of the protein, the gene symbol or an accession number to search.
- Navigate to the page of the protein of interest.
- Copy the accession number from this page (Next to ACCESSION). OR:
- Under the name of the protein, click on the FASTA link.
- Copy the amino acid sequence into the blank text field on the database website and click submit.
Example of how to find the FASTA sequence for Aquaporin-2 and using it in a Blast search:
Try out the Aquaporin-2 sequence for yourself:
MWELRSIAFSRAVLAEFLATLLFVFFGLGSALQWASSPPSVLQIAVAFGLGIGILVQALGHVSGAHINPA
VTVACLVGCHVSFLRAAFYVAAQLLGAVAGAAILHEITPVEIRGDLAVNALHNNATAGQAVTVELFLTMQ
LVLCIFASTDERRGDNLGSPALSIGFSVTLGHLLGIYFTGCSMNPARSLAPAVVTGKFDDHWVFWIGPLV
GAIIGSLLYNYLLFPSAKSLQERLAVLKGLEPDTDWEEREVRRRQSVELHSPQSLPRGSKA
Another example of FASTA sequence:
>gi|51948494|ref|NP_001004263.1| integrin beta-6 precursor [Rattus norvegicus]
MGIELVCLFLLLLGRNDHVQGGCAWSGAETCSDCLLTGPHCAWCSQENFTHLSGAGERCDTPENLLAKGC
QLPFIENPVSQVEILQNKPLSVGRQKNSSDIVQIAPQSLVLKLRPGGEQTLQVQVRQTEDYPVDLYYLMD
LSASMDDDLNTIKELGSRLAKEMSKLTSNFRLGFGSFVEKPVSPFMKTTPEEITNPCSSIPYFCLPTFGF
KHILPLTDDAERFNEIVRKQKISANIDTPEGGFDAIMQAAVCKEKIGWRNDSLHLLVFVSDADSHFGMDS
KLAGIVIPNDGLCHLDNRNEYSMSTVLEYPTIGQLIDKLVQNNVLLIFAVTQEQVHLYENYAKLIPGATV
GLLQKDSGNILQLIISAYEELRSEVELEVLGDTEGLNLSFTALCSNGILFPHQKKCSHMKVGDTASFNVS
VSITNCEKRSRKLIIKPVGLGDTLEILVSAECDCDCQREVEANSSKCHHGNGSFQCGVCACNPGHMGPRC
ECGEDMVSTDSCKESPGHPSCSGRGDCYCGQCVCHLSPYGSIYGPYCQCDNFSCLRHKGLLCGDNGDCDC
GECVCRDGWTGEYCNCTTSRDACASEDGVLCSGRGDCVCGKCVCRNPGASGPTCERCPTCGDPCNSRRSC
IECYLSADGQAQEECEDKCKATGATISEEEFSKDTSVPCSLQGENECLITFLITADNEGKTIIHNISEKD
CPKPPNIPMIMLGVSLAILLIGVVLLCIWKLLVSFHDRKEVAKFEAERSKAKWQTGTNPLYRGSTSTFKN
VTYKHREKHKVGLSSDG
|